如何解决CPU飙升或者频繁GC的问题
处理过线上问题的同学,可能都会遇到过线上运行的系统突然出现运行缓慢,CPU 100%,以及Full GC次数过多的问题,对于线上系统突然产生的运行缓慢,导致系统不可用,我们首先需要做的是导出jstack和内存信息,重启系统,恢复系统可用性。
这种情况可能的原因主要有两种:
- 代码中某块读取数据量较大,导致系统内存耗尽,从而导致Full GC 次数过多,系统缓慢;
- 代码中比较耗CPU的操作。
在此我们准备一个CPU耗时100%的代码来演示一下,FULL GC的问题代码暂不演示。
使用Spring Boot准备一个Controller如下:
package com.a3fun.learn.springboot.controller;
import com.a3fun.learn.springboot.exec.UserTaskExecutors;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author beidou
*/
@RestController
@Slf4j
public class UserController {
@GetMapping(value = "/run")
public String runAllTheTime(){
UserTaskExecutors.executorService.execute(() -> {
while (true){
int i = 0;
i++;
if (i == Integer.MAX_VALUE){
log.info("线程结束执行:" + Thread.currentThread().getName() + ", i = " + i);
break;
}
}
});
return "run ok";
}
}
UserTaskExecutors如下所示:
package com.a3fun.learn.springboot.exec;
import org.springframework.stereotype.Component;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
*
*/
@Component
public class UserTaskExecutors {
public static ExecutorService executorService = null;
public static int CPU_CORE_SIZE = 4;
{
executorService = new ThreadPoolExecutor(CPU_CORE_SIZE, CPU_CORE_SIZE, 60, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10*1000*100), new NameThreadFactory());
}
class NameThreadFactory implements ThreadFactory{
private final AtomicInteger mThreadNum = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r, "my-thread-" + mThreadNum.getAndIncrement());
return t;
}
}
}
通过以下排查步骤我们可以确定是Full GC 还是 代码中大量消耗CPU的操作。
- 执行
top命令查看CPU占用的情况。如下是一个示例: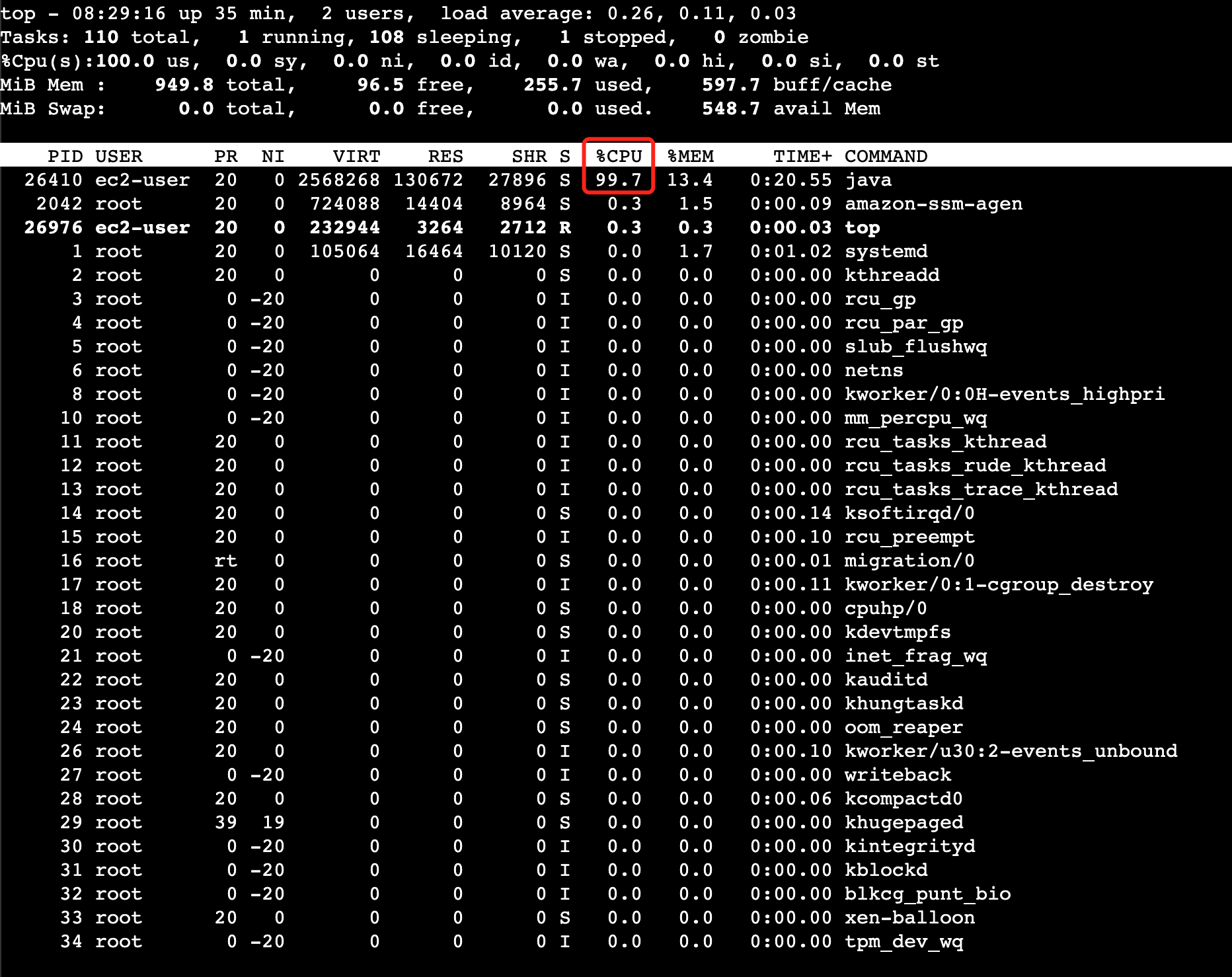 可以看到,有一个PID为
可以看到,有一个PID为26410的Java程序CPU占用近乎100%。 - 执行
top -Hp 26410查看该进程的各个线程情况。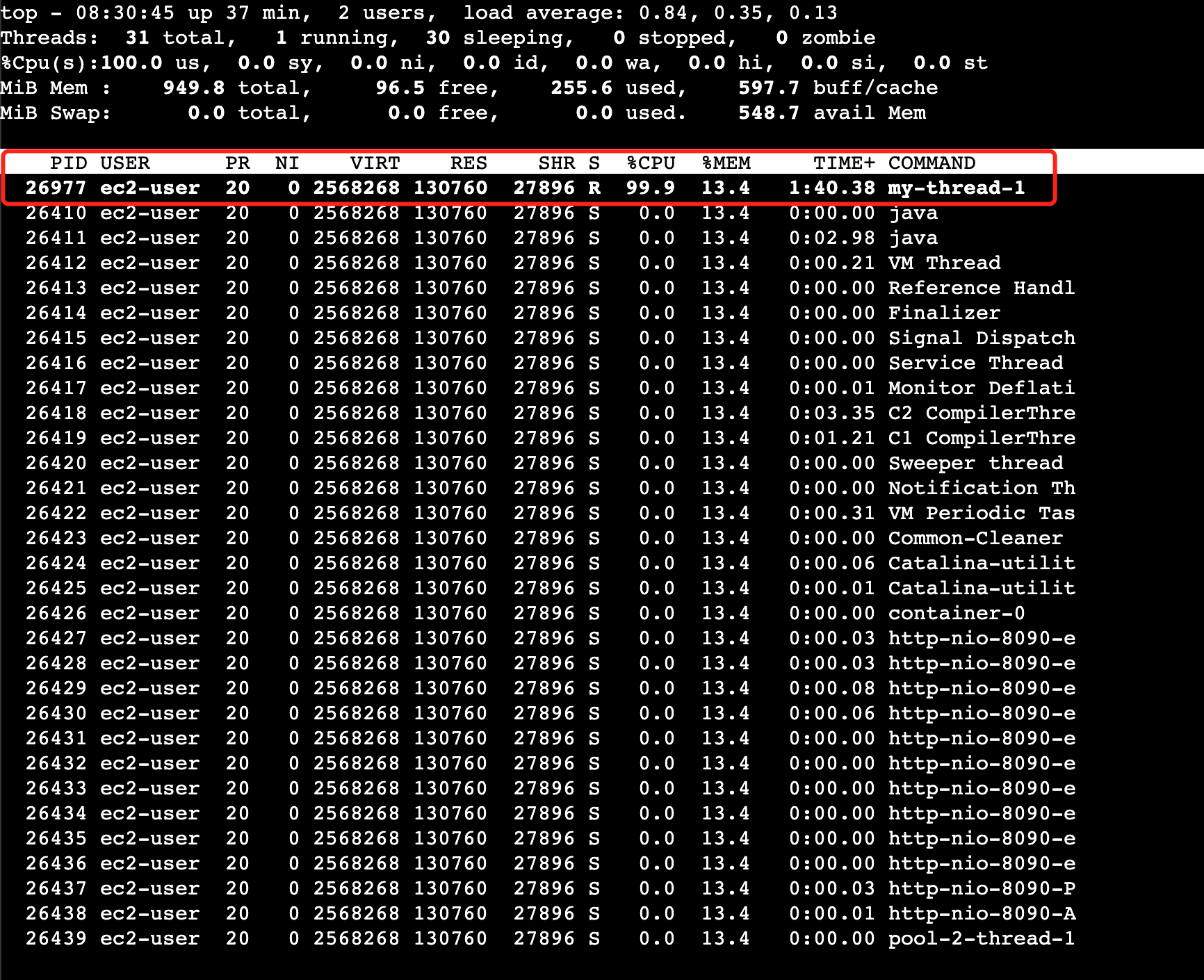 我们可以看到在进程为
我们可以看到在进程为26410的Java程序中各个线程的CPU占用情况,其中有一个id为26977的名为my-thread-1的线程导致CPU占用近乎100%。接下来我们将26977转换为16进制6961。 - 通过
jstack 26410或者jstack 26410|grep 6961命令查看堆栈信息。 如果是Full GC次数过多,那么通过jstack得到的线程信息会是类似于VM Thread之类的线程。由于在上一步我们已经知道是我们的线程my-thread-1,所以我们只要找到该线程信息即可。注意在此nid=Ox6961即为上面16进制的pid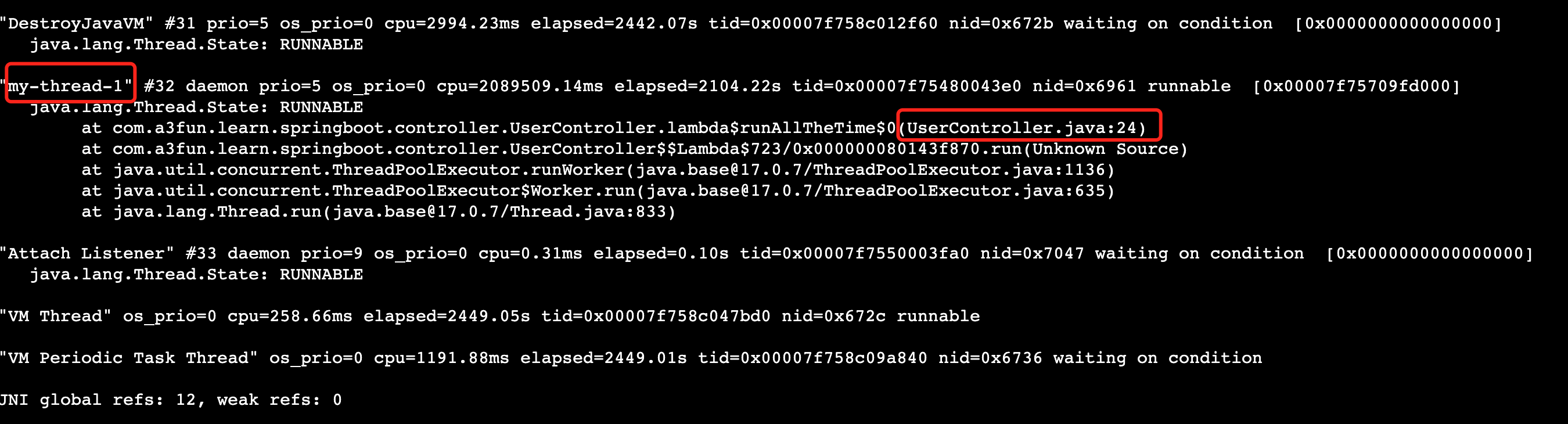 在此我们找到是我们的
在此我们找到是我们的UserController第24行代码出现问题,我们就可以针对性的去查看此处位置排查问题。 - 如果是FULL GC问题,我们可以通过
jstat -gcutil 进程号 统计间隔毫秒 统计次数查看统计信息。
- 如果需要导出内存信息,可以通过执行
jmap -dump:format=b,file=filename.hprof 进程号(26410),导出某进程下内存heap到文件中。然后通过工具MAT(MemoryAnalyzer)进行分析
除了上面FULL GC或CPU 100% ,另外还有几种情况可能会导致某个功能运行缓慢,但是不至于系统不可用:
-
代码中某个位置可能阻塞性的操作,导致该功能比较耗时。
对于这种情况,比较典型的例子就是,我们某个接口访问经常需要2~3s才能返回。
这是比较麻烦的一种情况,因为一般来说,其消耗的CPU不多,而且占用的内存也不高,也就是说,我们通过上述两种方式进行排查是无法解决这种问题的。
而且由于这样的接口耗时比较大的问题是不定时出现的,这就导致了我们在通过
jstack命令即使得到了线程访问的堆栈信息,我们也没法判断具体哪个线程是正在执行比较耗时操作的线程。对于不定时出现的接口耗时比较严重的问题,我们的定位思路基本如下:
首先找到该接口,通过压测工具不断加大访问力度,如果说该接口中有某个位置是比较耗时的,由于我们的访问的频率非常高,那么大多数的线程最终都将阻塞于该阻塞点
这样通过多个线程具有相同的堆栈日志,我们基本上就可以定位到该接口中比较耗时的代码的位置。
-
某个线程由于某种原因而进入WAITING状态,此时该功能整体不可用,但是无法复现;
①这样的情况,我们可以通过
grep在jstack日志中找出所有的处于TIMED_WAITING状态的线程,将其导出到某个文件中。②等待10秒后,再次对jstack日志进行grep导出。
③重复导出几个文件后,我们对文件进行分析,找出其中在这几个文件中一直都存在的用户线程,这个线程基本上就可以确认是包含了处于等待状态有问题的线程。因为正常的请求线程是不会在20~30s之后还是处于等待状态的。
④经过排查得到这些线程之后,我们可以继续对其堆栈信息进行排查,如果该线程本身就应该处于等待状态,比如用户创建的线程池中处于空闲状态的线程,那么这种线程的堆栈信息中是不会包含用户自定义的类的。 这些都可以排除掉,而剩下的线程基本上就可以确认是我们要找的有问题的线程。通过其堆栈信息,我们就可以得出具体是在哪个位置的代码导致该线程处于等待状态了。
-
由于锁使用不当,导致多个线程进入死锁状态,从而导致系统整体比较缓慢。
对于死锁,这种情况基本上很容易发现,因为
jstack可以帮助我们检查死锁,并且在日志中打印具体的死锁线程信息。